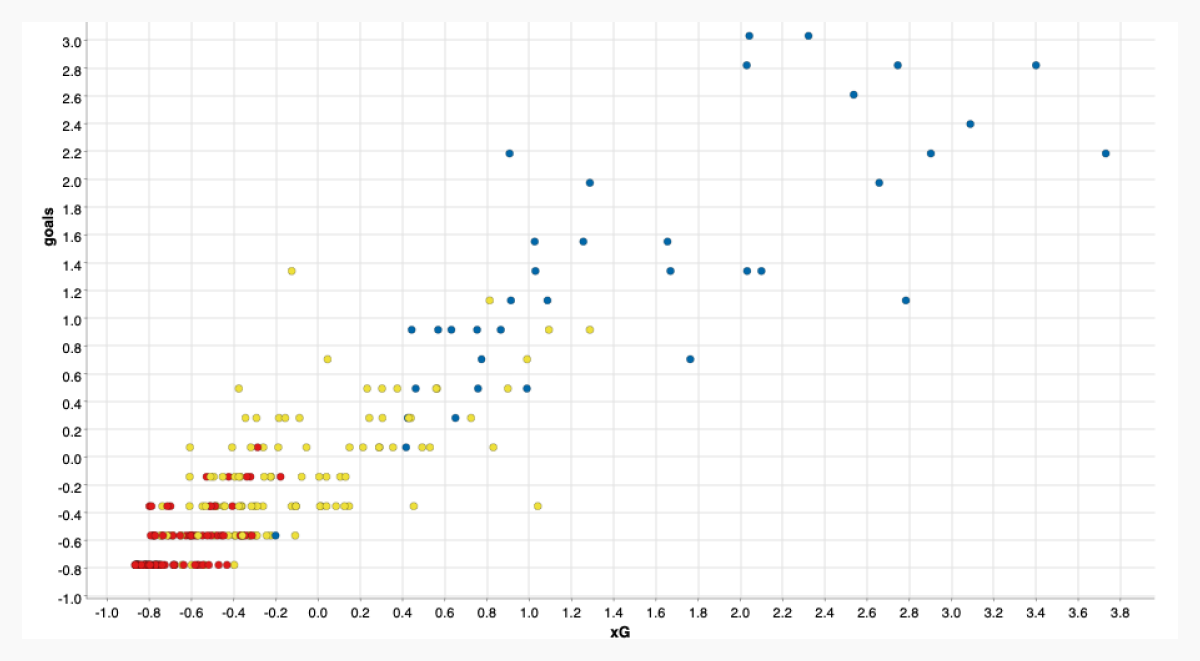
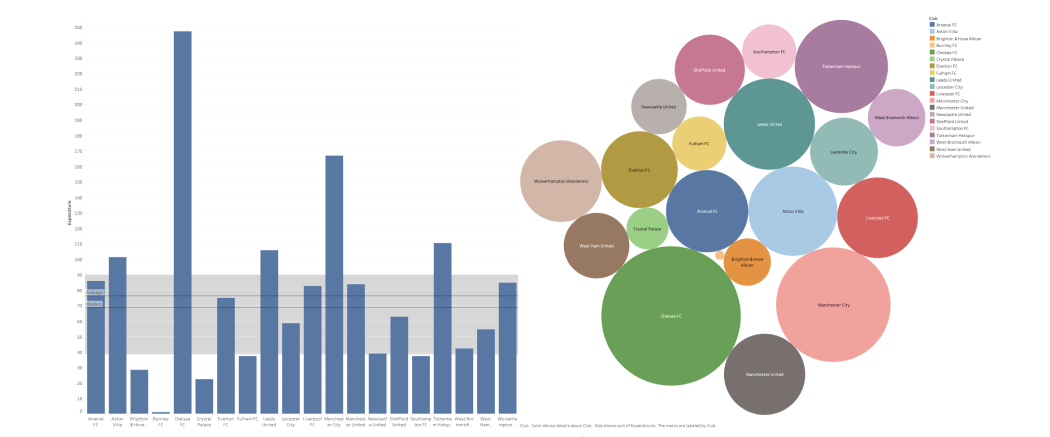
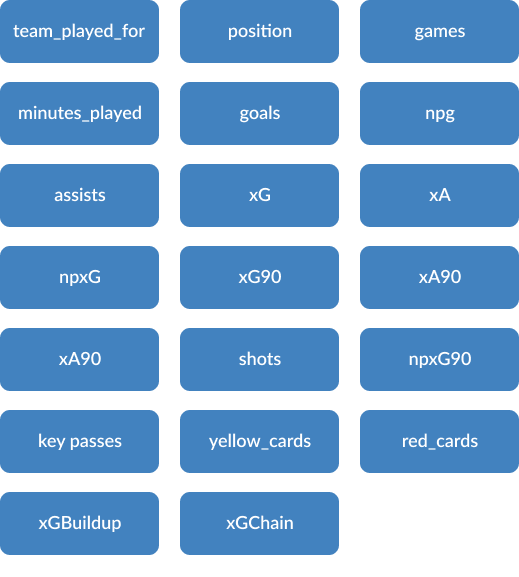
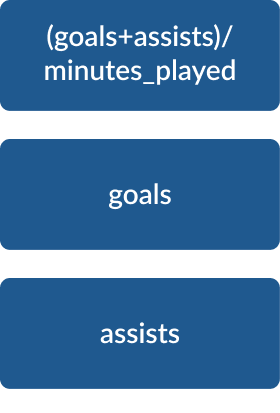
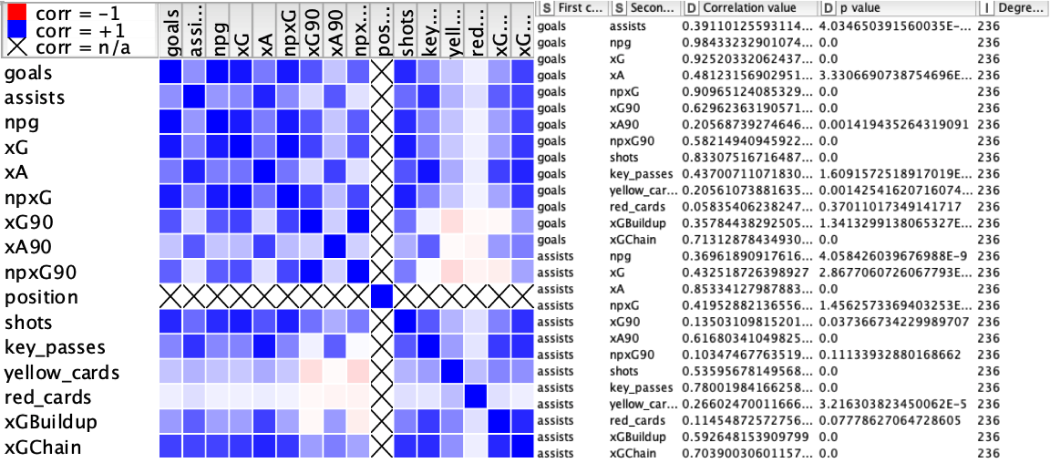
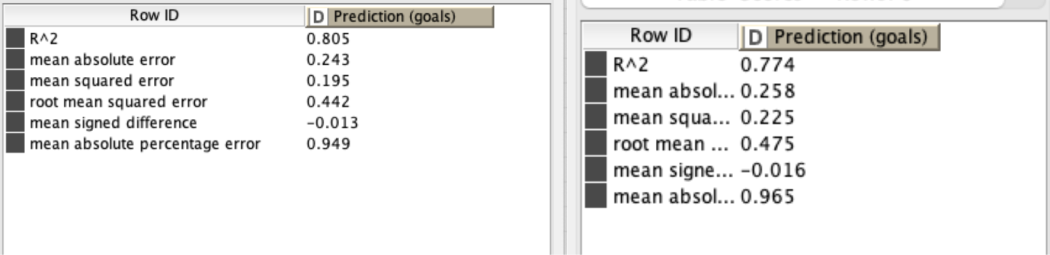
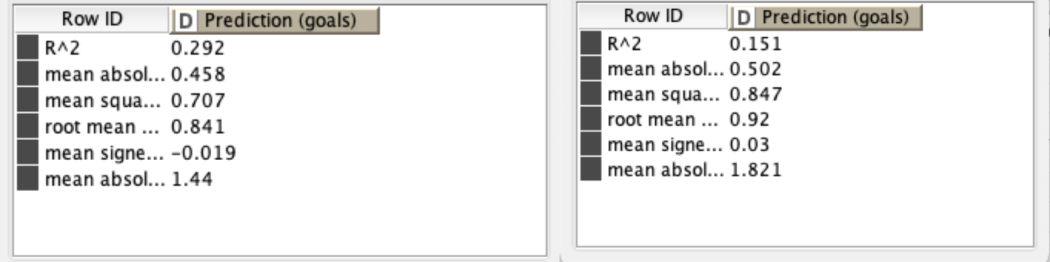
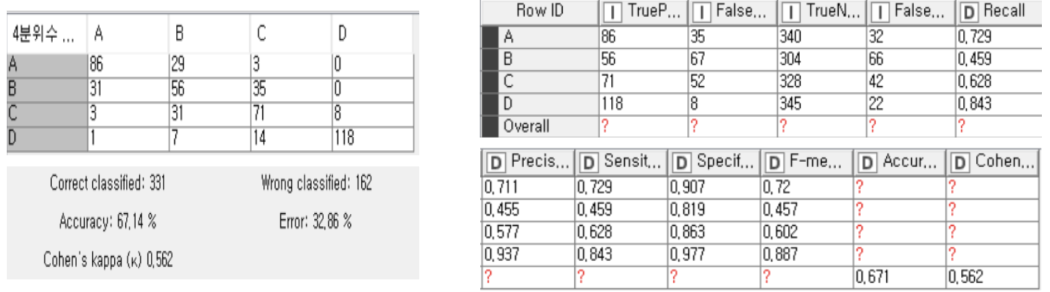
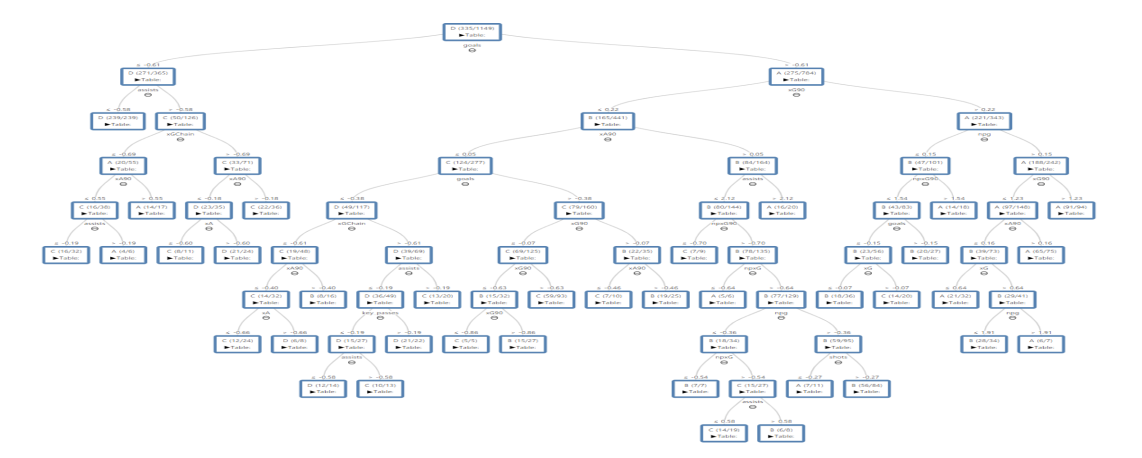
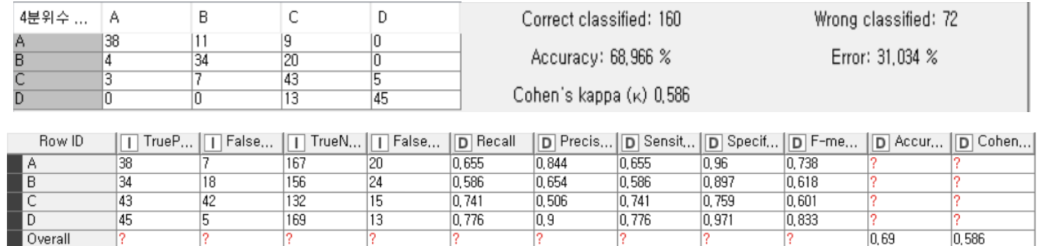
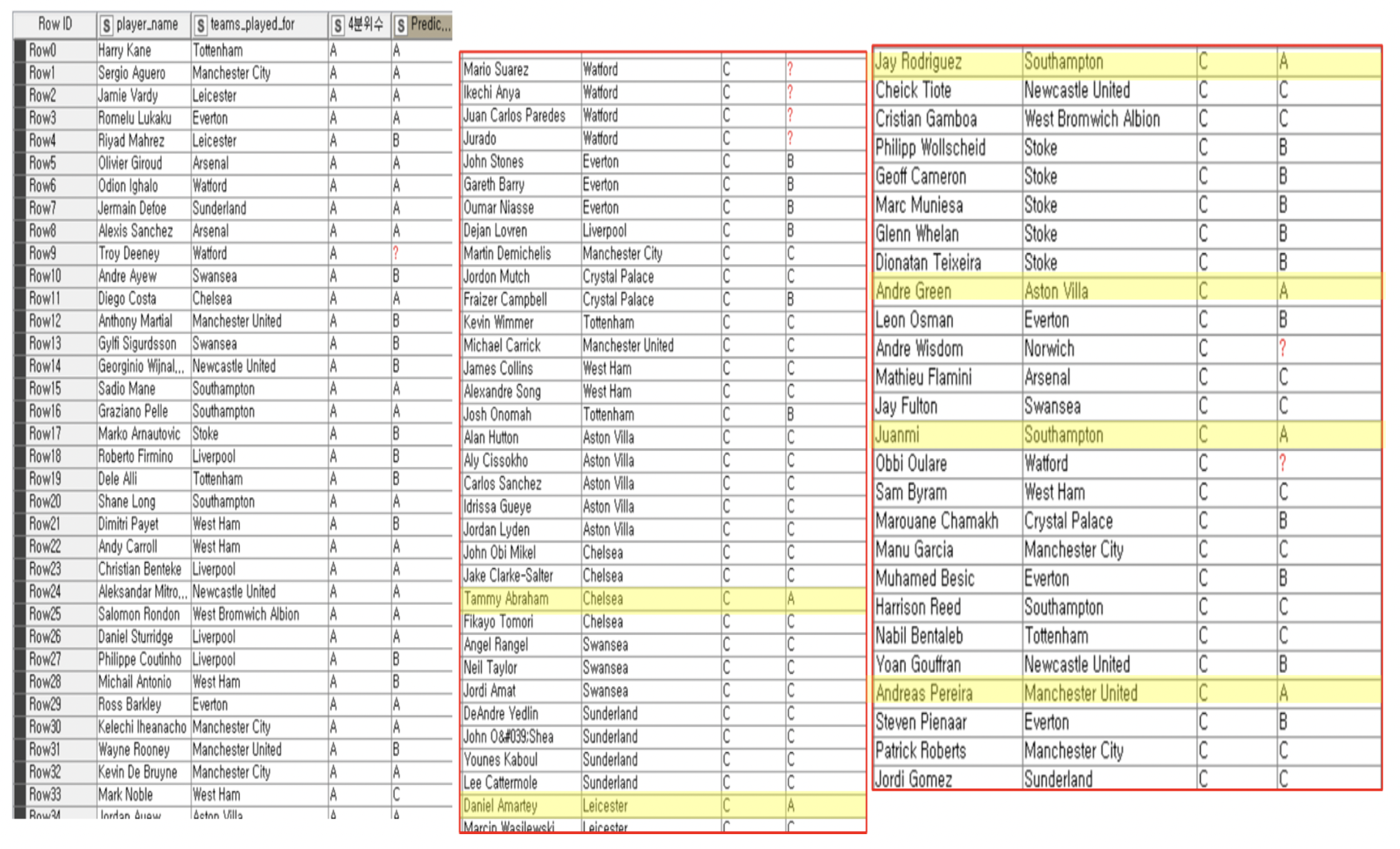
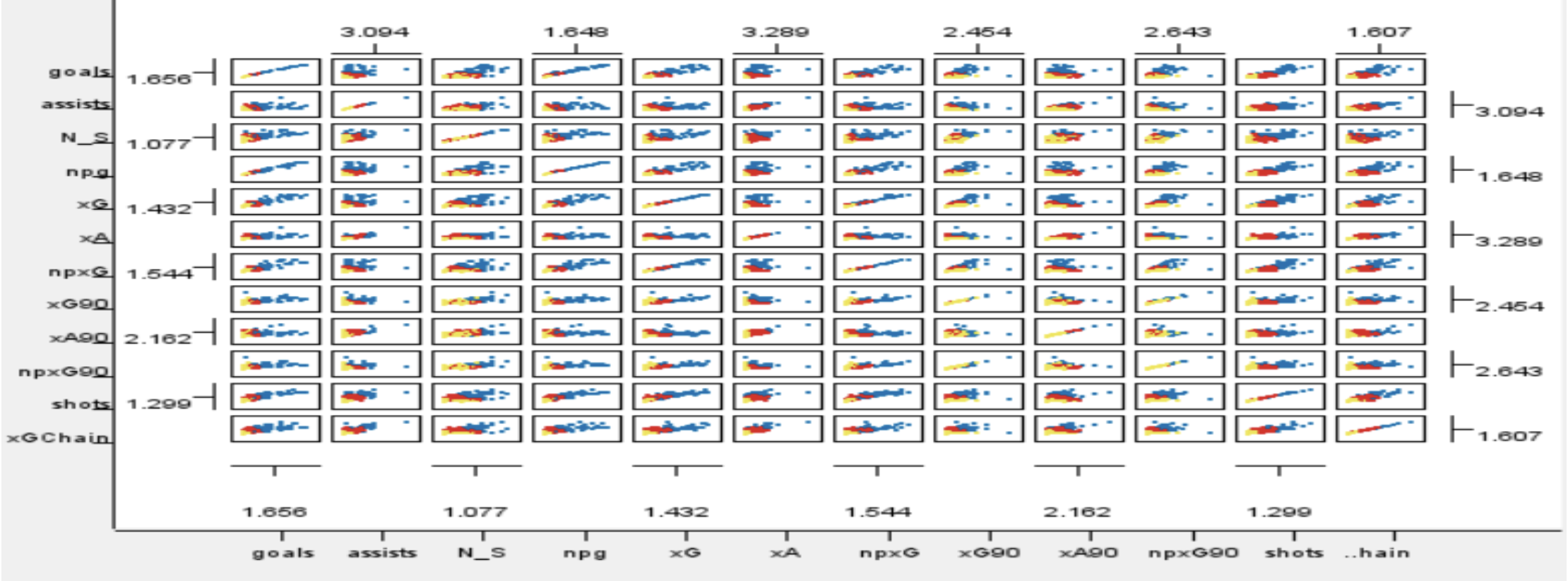
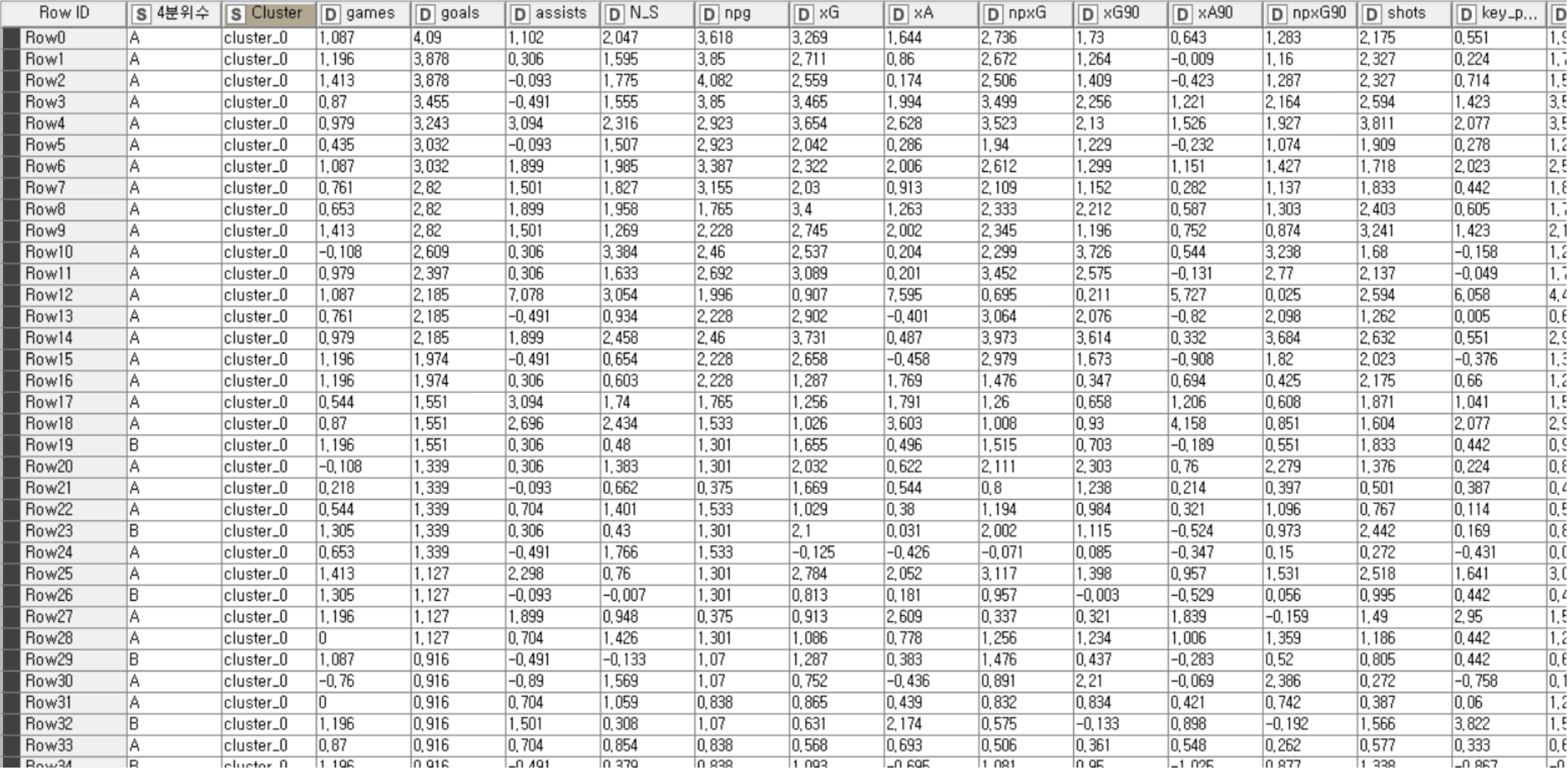
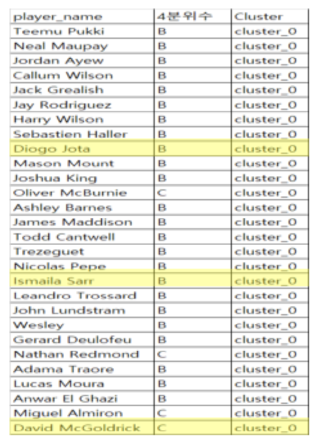
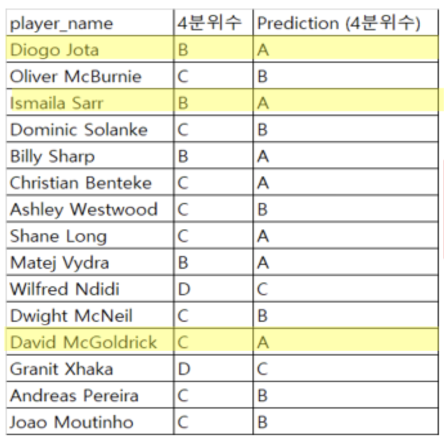
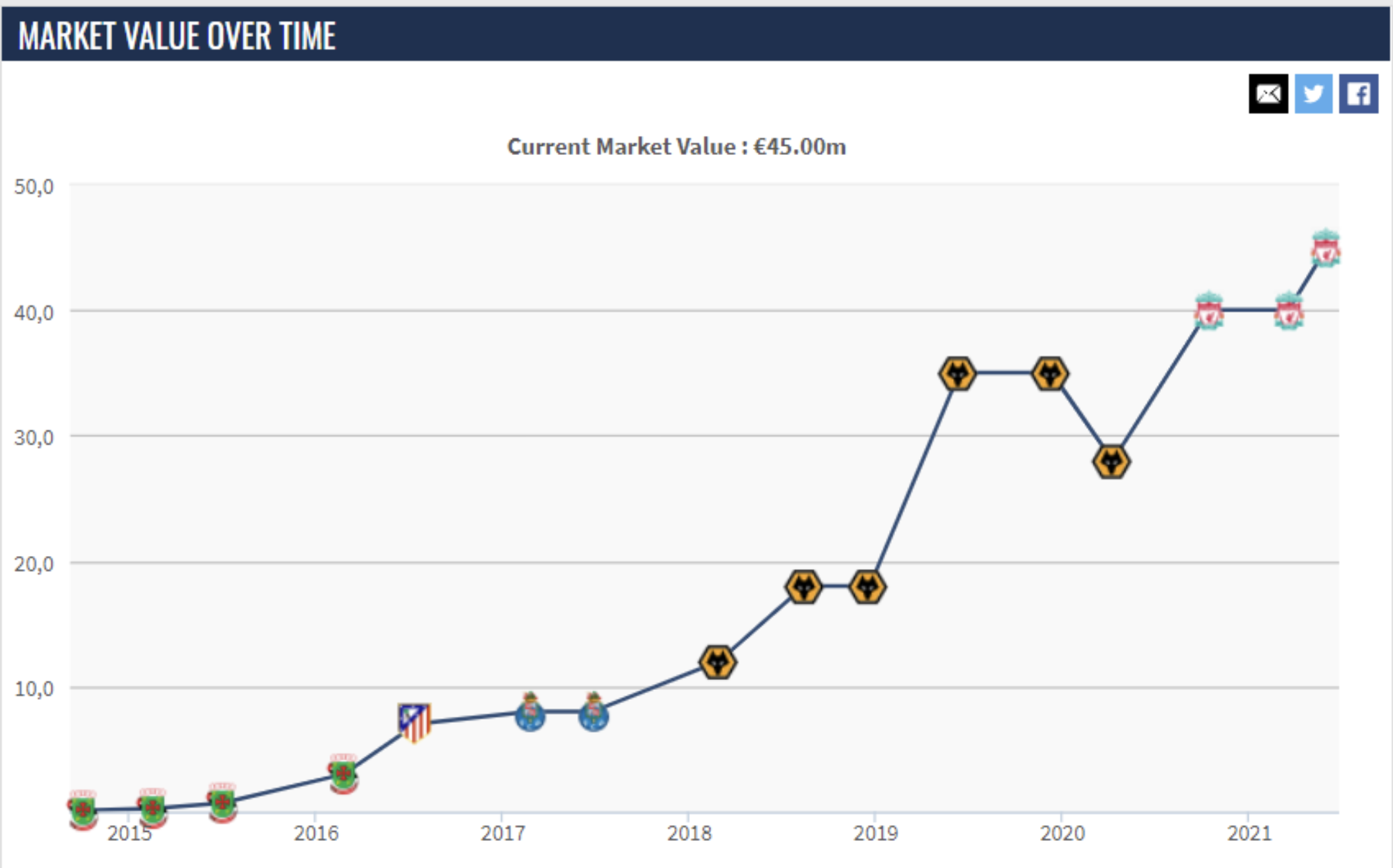
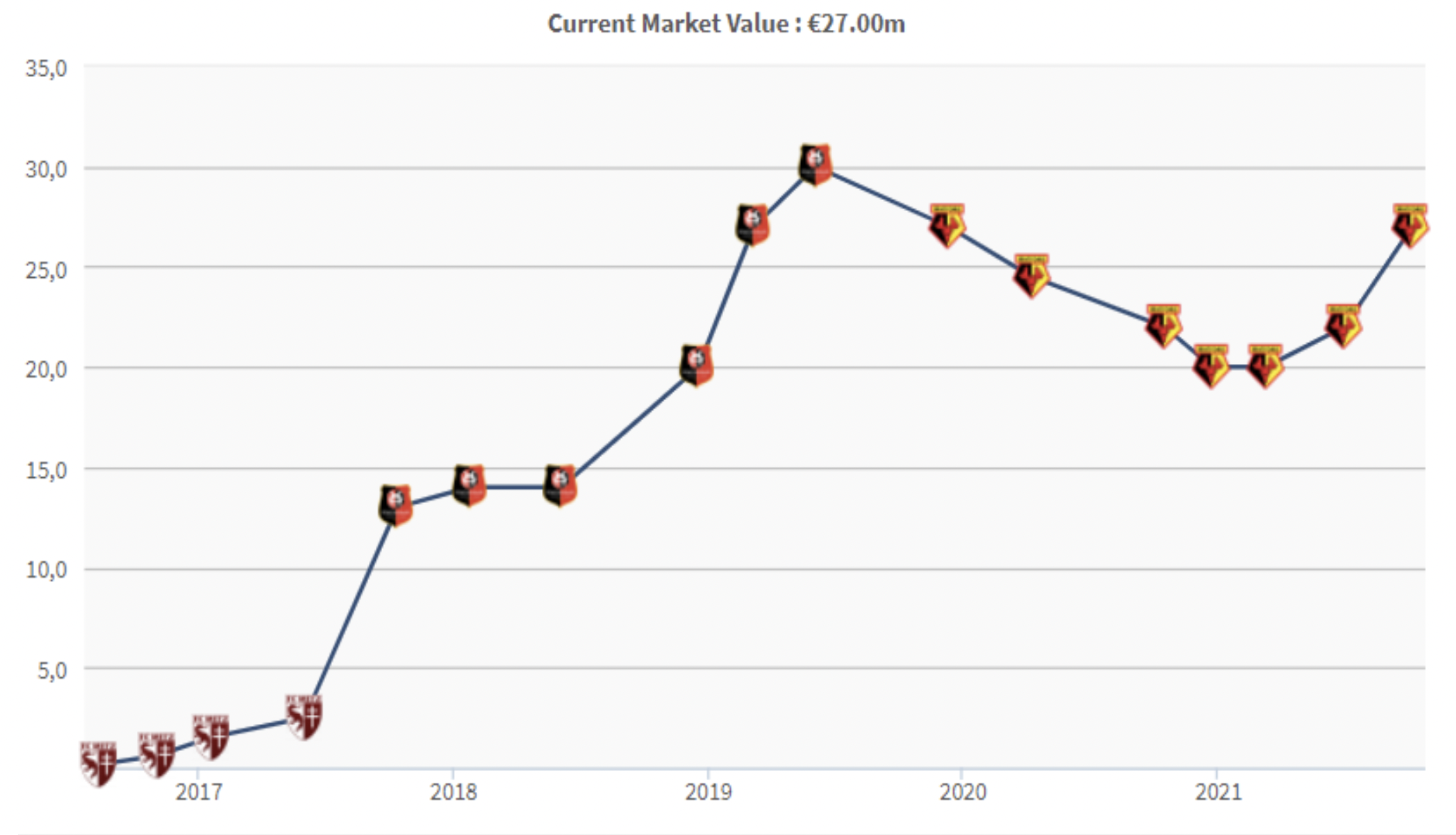
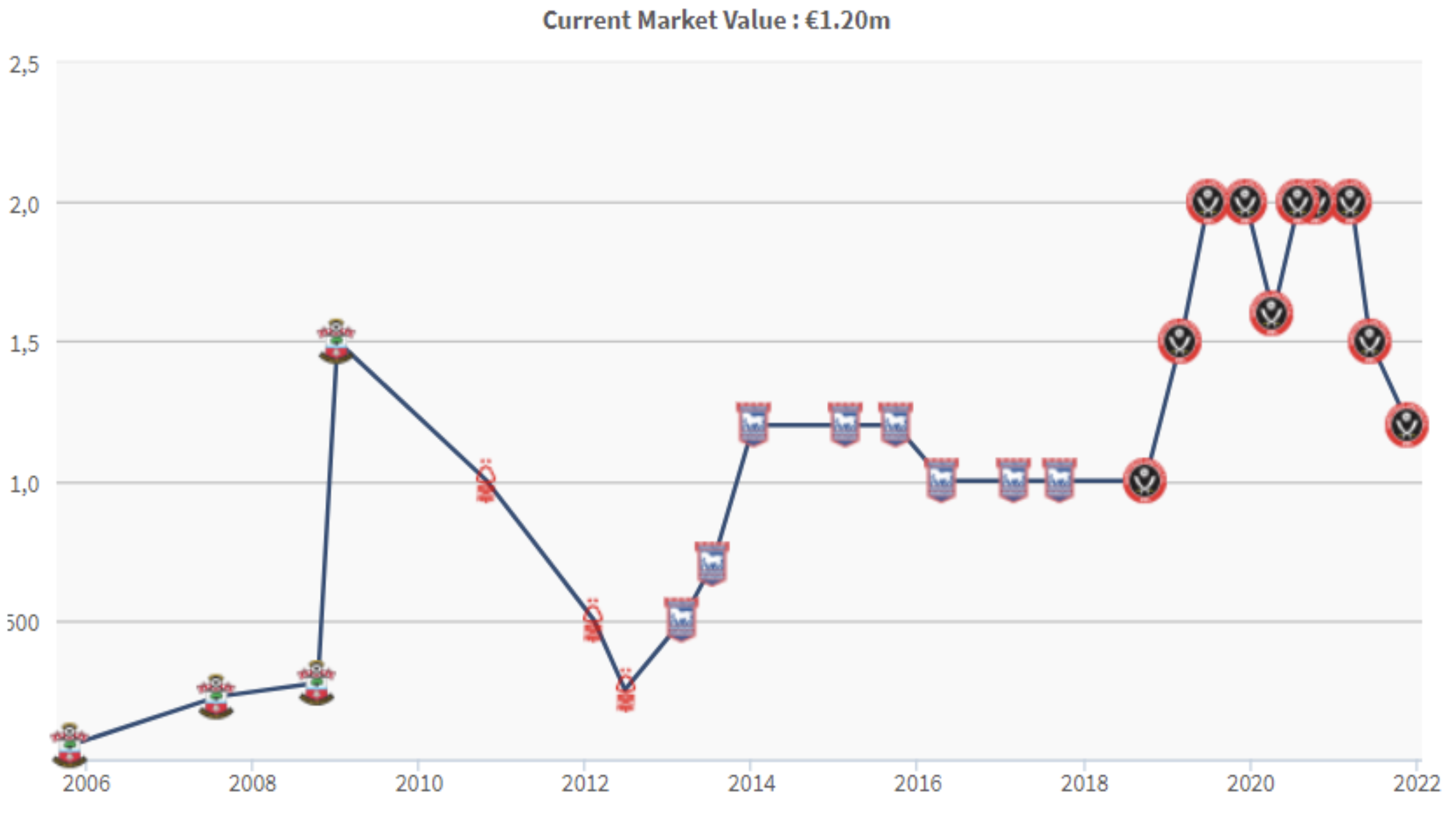
As a result of this data analysis, the most relevant variables of goals and assists were xG, npxG90, xG90, npxG, npg, and xA90. The three players from these analysis had a good performance in the 19-20 season, and other players who moved into upper groups through either Decision Tree or k-Means Clustering were also performing well within the league.
Although the analysis results were successful, since it was grouped into 4 quartiles, the accuracy was low in the Decision Tree and the k-means clustering results showed a linear appearance between most important variables. Also, we should have used the Random Forest prediction model to find related variables, not with both prediction and classification models. Moreover, since only soccer-related stats excluding the player’s age and injury history are used for those analyses, variables such as a decline in physical ability or an aging curve may exist, so it is clear that the data analysis result is not an perfect key to solve the problem.
However, this analysis was quite meaningful. It was the first data analysis project and in fact, although it is difficult to analyze data in soccer industry, we tried various analyses with a spirit of challenge. We were also able to measure players’ performance to some extent by comparing the actual performance of the players found by data analysis. We were confident that it was a sufficiently successful analysis because the process of solving actual business problems through data analysis itself was meaningful and showed sufficient possibilities.
In the next analysis, the decision tree analysis will be conducted by supplementing the above limitations and grouping the players into three quartiles, not four, and more effective data analysis and results will be derived by using Random Forest. Data such as age and injury history will also be added to strive for the better results.